交付一套英国客户定制的关于OpenMP、MPI、CUDA三者的集群批处理、机器学习、并行计算程序
责任编辑:济南快创软件IT部
交付一套英国客户定制的关于OpenMP、MPI、CUDA三者的集群批处理、机器学习、并行计算程序,客户要的很急,我们程序员加班搞到半夜两点,总算赶出来了,相关的程序和材料都汇总整理好后发给客户了。 并行计算就是能让你的计算速度成几何倍数的提高,将原来需要几天才能完成的计算任务,在短短几小时甚至几分钟内完成,是计算行业从业人员的福音,就是上手有点难度。
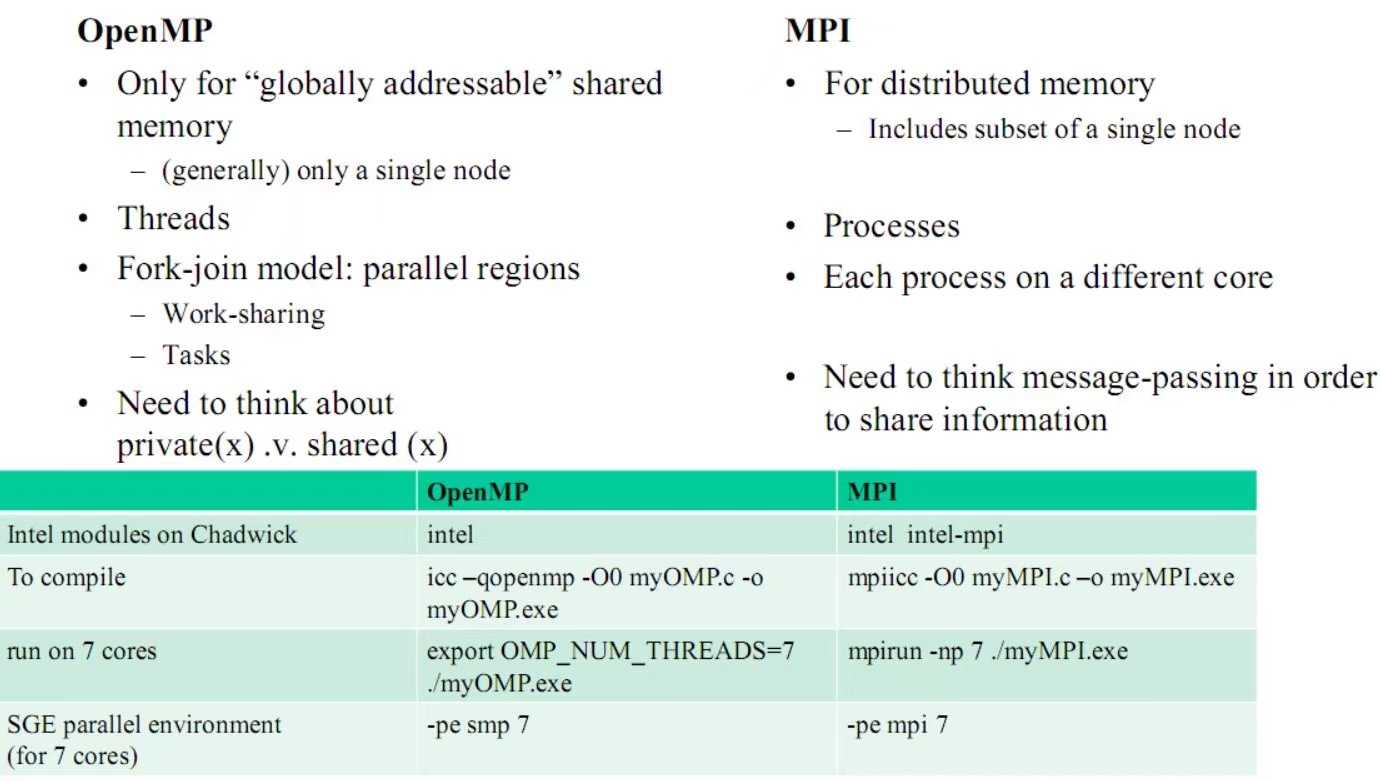
OpenMP和MPI是并行编程的两个手段,对比如下: OpenMP:线程级(并行粒度)、共享存储、隐式(数据分配方式)、可扩展性差;MPI:进程级、分布式存储、显式、可扩展性好。OpenMP采用共享存储,意味着它只适应于SMP,DSM机器,不适合于集群。MPI虽适合于各种机器,但它的编程模型复杂: 需要分析及划分应用程序问题,并将问题映射到分布式进程集合;需要解决通信延迟大和负载不平衡两个主要问题;调试MPI程序麻烦;MPI程序可靠性差,一个进程出问题,整个程序将错误。SMP(Symmetric multi-processing)是共享总线与内存,特点是单一操作系统映象、在软件上是可扩展的而在硬件上不可扩展。DSM(distributed shared memory)是SMP的扩展,特点是物理上分布存储、单一内存地址空间、非一致内存访问、单一操作系统映象。
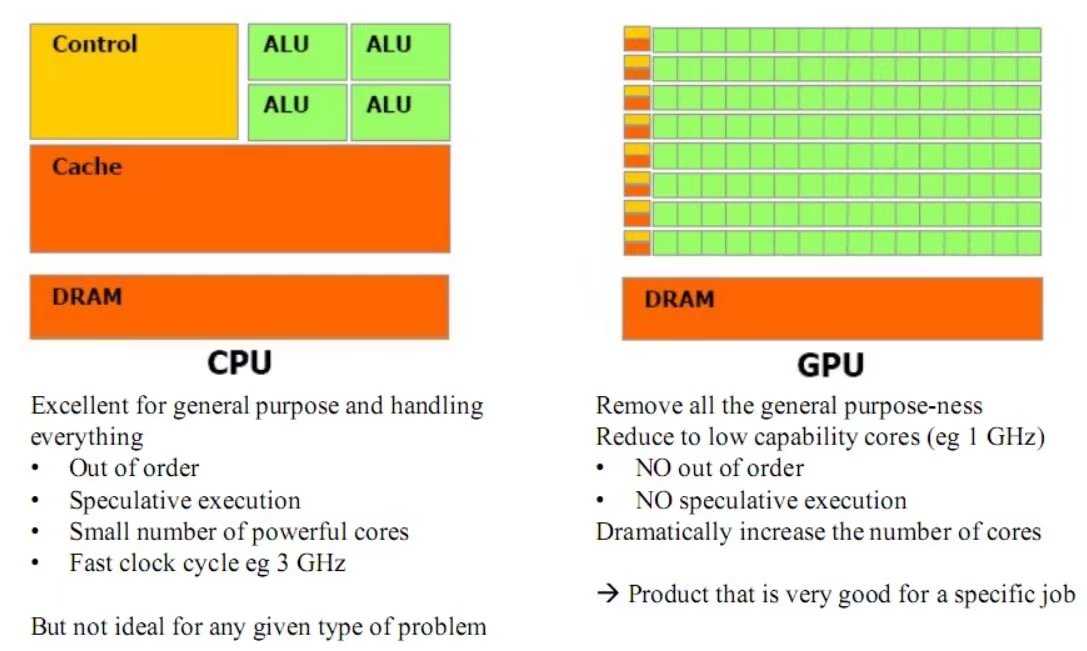
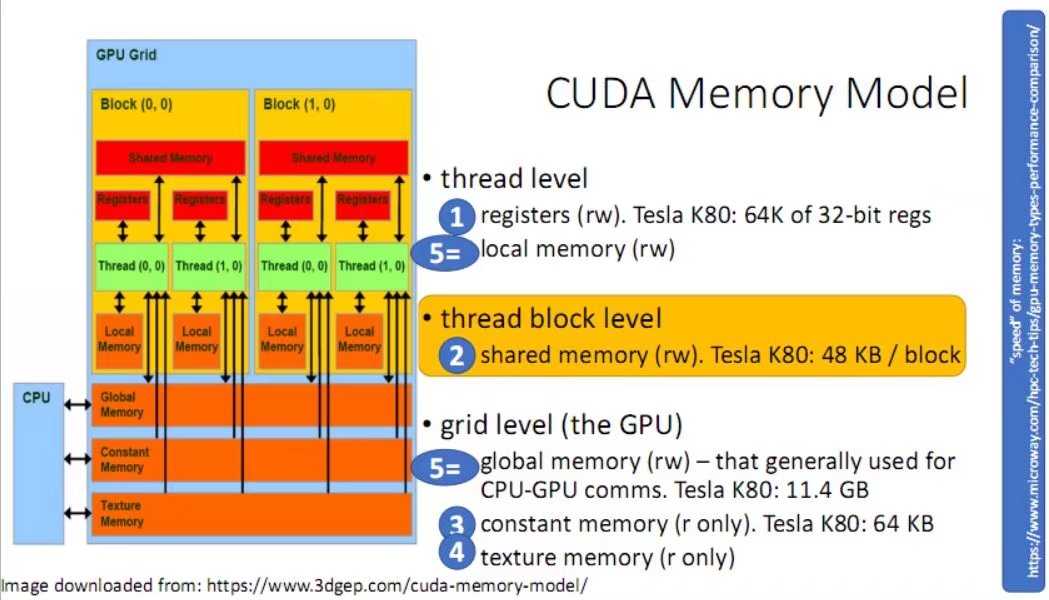
CUDA是建立在NVIDIA的CPUs上的一个通用并行计算平台和编程模型,基于CUDA编程可以利用GPUs的并行计算引擎来更加高效地解决比较复杂的计算难题。近年来,GPU最成功的一个应用就是深度学习领域,基于GPU的并行计算已经成为训练深度学习模型的标配。GPU并不是一个独立运行的计算平台,而需要与CPU协同工作,可以看成是CPU的协处理器,因此当我们在说GPU并行计算时,其实是指的基于CPU+GPU的异构计算架构。在异构计算架构中,GPU与CPU通过PCIE总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device)。